Code Review Ethos
I wrote this a few years ago to share with friends and colleagues. It got a lot of positive feedback. I figure I might as well post it here.
Why do we review?
There are many reasons to request and offer code review. It helps coalesce our many variations into a gestalt style, building our culture and interpersonal relationships. It results in higher quality code that benefits the company and the code’s future maintainers. It distributes knowledge to increase our organization’s resilience to personnel changes. On a personal level, it grows our own abilities; this is true for both reviewing and being reviewed.
From any angle one cares to look at it, code review is important. It has benefits in the short, mid, and long term. It has benefits to organizations, and the individuals within them. In this way it is very much an investment that returns cumulative interest.
What are we reviewing?
Depending on the context, there are a number of overarching areas that a reviewer should consider. In order these are:
- Should this work even exist? In a closed source setting, this question is often answered before work even begins. If however you do any work on open source code, it’s important to identify whether that drive-by feature Pull Request (PR) really belongs, or is one person’s opinion.
- Is this the “best” implementation? In this step you’re looking at high level design. Are the algorithms and data structures chosen the most appropriate? Are any third party libraries added good ones (active, well maintained, widely used)? Has security been taken into account?
- Is it structured well? Code should aim for high cohesion and low coupling. In short that means any file, struct/class, function, etc... has a well defined purpose (high cohesion), while same-project imports are kept logical and to a minimum (low coupling). See Addendum 1 for why high cohesion, low coupling code is desirable.
- By this point we’ve established the addition is fundamentally desirable, is a sufficiently good implementation, and is well structured. This final review step focuses on the fine detail. Are there logic errors, security issues, or more generally bugs? Hopefully there’s enough test coverage to ensure the code operates as the author expected, but are those expectations correct? Can you see assumptions in the code that may be dangerous, like a pointer being dereferenced without a check to see if it might be nil?
Note some of the things we’re not reviewing for: coding style, test coverage, CVEs in dependencies. These should be automated away based on organization policy. There are tools to enforce coding style and test coverage and they should be used.
How should we create a PR?
Reviewing code is hard. Many times harder than writing it. Good code review takes time and concentration. After all, we're expecting a reviewer to find mistakes we missed ourselves. With that in mind, it’s important we've done our absolute best before asking somebody to review our code.
To keep a cap on the complexity of a PR, it should be of reasonable length. It turns out there’s an inflection point in review time as PRs exceed 400 lines. Use that as a benchmark for maximum desirable size. It’s generally more important to keep PRs representing changing or new functionality short, while renaming and refactoring PRs tend to have a natural size dictated by the existing code.
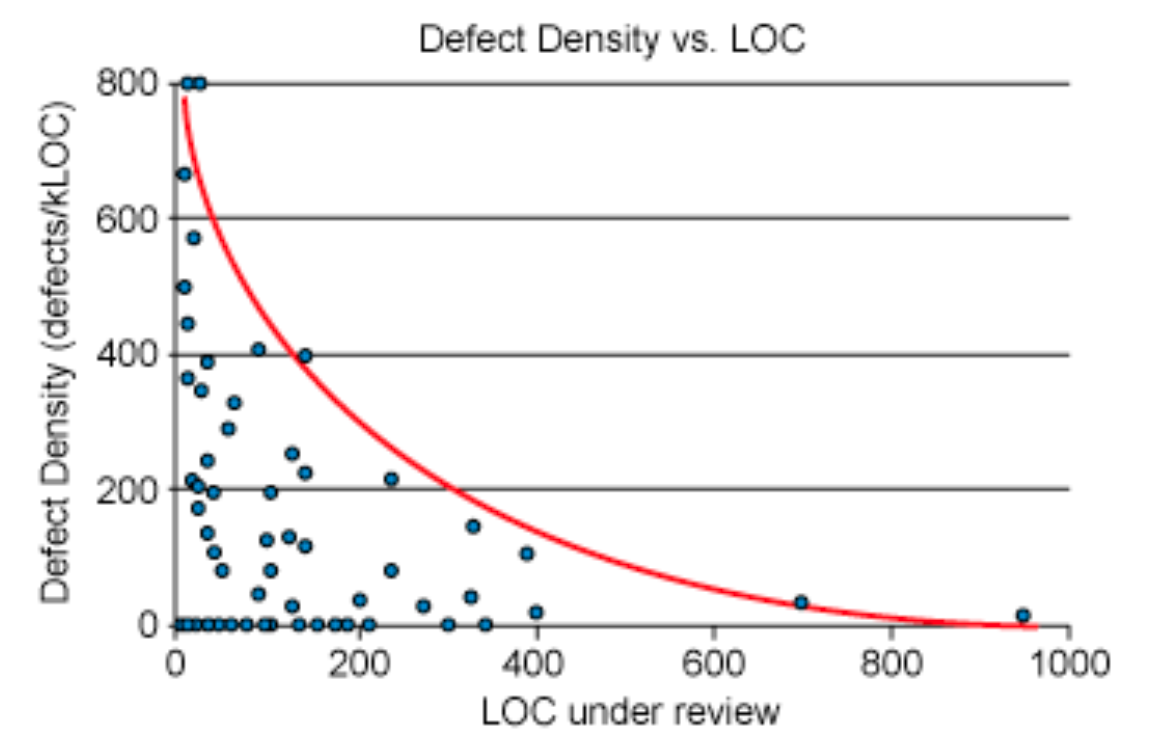
Additionally, PRs should have a theme to aid a reviewer in comprehending intent. This is not a hard rule, sometimes a PR will inevitably be a mashup of many things. However, it’s a good rule of thumb that will enable your PRs to get better review and be merged faster. The themes fall roughly into the following buckets:
- Bookkeeping: comments or documentation needed adding/updating; essentially any non-code changes in the repo. There are no code changes in this PR. Bookkeeping work can also be done as part of Refactoring, Changing Functionality, and New Functionality PRs, but should be avoided in Renaming PRs to keep them super quick to review.
- Renaming: is there some function or variable that benefits from renaming? Mixing these types of changes in with other work creates noise. It can distract from the other, probably more critical, work receiving good reviews, and at the same time, prevent any issues with the renaming being detected. Renamings inside refactorings are especially prone to unintentional bugs being missed as it requires extremely careful reading to detect a name changed inside the refactored code.
- Refactoring: some code needs to be restructured, be it breaking it into more functions and/or files, or moving it to a different location in the repository. By PR’ing this individually a reviewer knows to ensure behaviour hasn’t been changed accidentally.
- Changing Functionality: ideally a single PR for each behaviour change. This may span many functions and packages, but the change should be cohesive, representing a particular update. Like a scientific experiment, changing too many variables (behaviours) at once makes it challenging to determine what’s going on.
- New Functionality: PR’ing new functionality on its own ensures the reviewer can see clearly what you’re adding and where it attaches to the existing code base. By isolating it a review can more easily detect issues with the new code and determine if it implements all the desired behaviour correctly.
Sometimes a large project will involve a mix of these themes. If it’s impossible or costly to work out how to make changes that can be merged into the master branch, a long-running feature branch that collects all the changes with code PR’d and reviewed against it can be an effective way to aid your reviewers. A warning however, long-running feature branches must be kept up to date with upstream changes. That responsibility falls to the developer(s) working in the branch, not the developers creating the upstream changes.
Notes on preparing your PR for a review
Research has shown that the rate of defects in code decreases substantially if the author annotates their PR before a review ever looks at it.
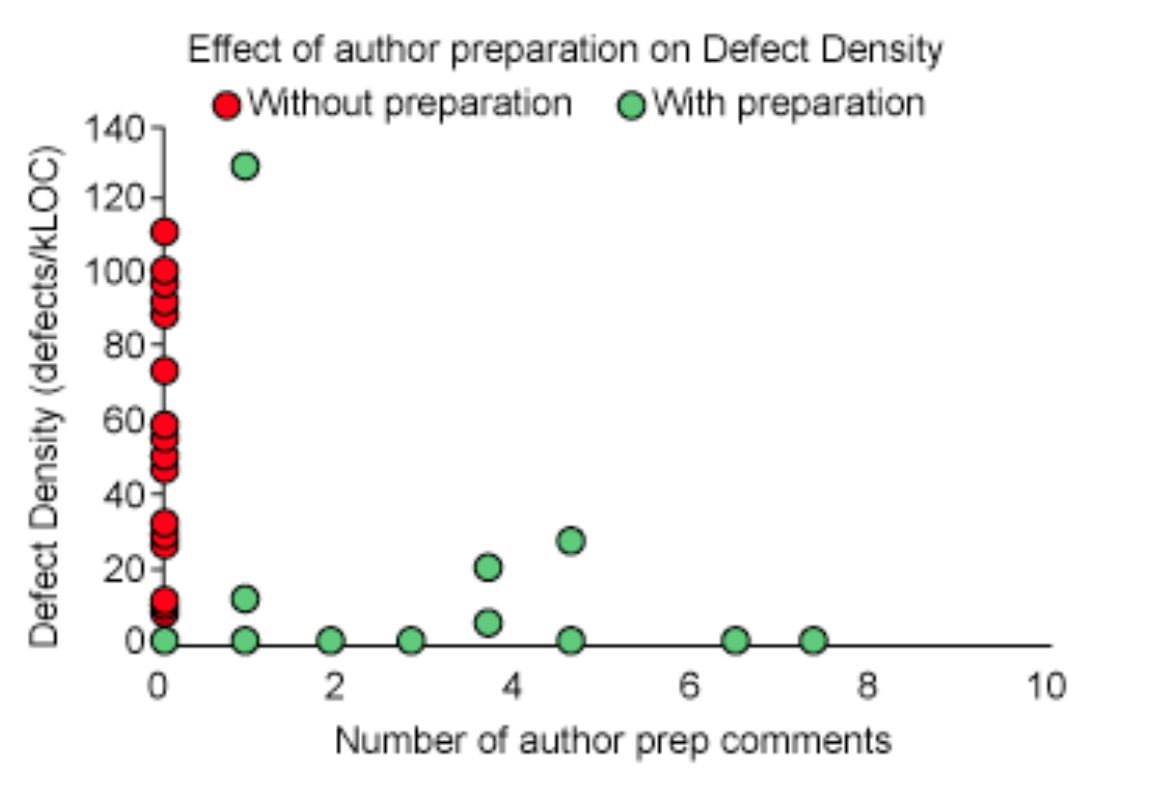
This could simply be a comment in the initial creation of your PR for a smaller change. Or it could be a handful of line specific comments. The goal is to provide some guidance to the reviewer to comprehend your change.
How should we review a PR?
With empathy. Nobody is writing bad code on purpose. This doesn’t mean we should let standards slip or give less than our best review. It does mean we should approach every code review as a learning opportunity. In every code review we are simultaneously mentor and mentee.
Language is important, especially when missing the nuance of intonation. We want to help our colleagues produce the best possible code. At the same time, we need our review to be clear. Avoid confrontational language. When there is clearly a bug, neutral language stating the precise issue in a clear manner is desirable. Language suggesting the bug exists because there is a deficiency in a colleague is unacceptable. For more thoughts on how to phrase review comments, this is a good article from PagerDuty.
Our review should extend beyond the objective aspects or concepts outlined in the “What are we reviewing for?” section above. Whenever we provide review, we should also be thinking about whether there are opportunities to highlight concepts that can help the code author grow and develop their own knowledge or skills.
Similarly, if we see something we don’t understand, we should ask questions. This is an opportunity to potentially learn something new. While writing code is an engineering exercise, it leaves more room than many other engineering disciplines for personal expression. Somebody writing code differently to us does not intrinsically make it wrong.
Taking in the context
Code does not exist in a vacuum. Especially in the case of changing existing code or adding new code, it’s critical to expand your review to take in the context around the change. Some concrete examples:
- The change is adding a field to a struct. The name makes sense, it has the expected type, etc... Has the field been added to the correct struct though? You may well have to expand the segment Github is showing you to determine this.
- Another error check has been added and you see the pretty standard `if err != nil {return err}`. Does this leave a dangling transaction/file handle that should have been rolled back/closed? Expand the code above the change and check.
- A new check compares a value to a constant defined in the code. Has the value been normalized to the expected case/format? Is it appropriate to normalize or do we want to strictly take the value as provided?
Avoiding code review burnout
It turns out that humans can’t concentrate on any mentally intensive activity for more than about 90 minutes. In the case of code review, studies show that our rate of detecting defects drops off as we pass the hour mark. This doesn’t mean we should try and review more code in that time. We also see a drop off in review quality as reviewers attempt to exceed ~500 LOC/hour. Take these factors into account before you engage in each review. If you’ve already been reviewing code for 45 minutes, don’t dive into a fresh 400 line review. Do something else and come back to that PR when you can give it the attention it deserves.
What should we be learning?
The most critical takeaway when we receive review is to identify patterns from one-offs. Sometimes it’s obvious, sometimes less so. In a perfect world, we would never receive the same point of review more than once. Unfortunately we’re fallible humans and we will forget things and make the same mistake more than once. Sometimes a piece of review is a one-off; we made a logic error that’s unique. There may still be an emergent pattern to this error that we can learn to avoid. Detecting those falls largely on the author, who should introspect and retrospect to see if they can detect a pattern.
More critically though are the obvious patterns. Reviewers get tired of telling us to fix the same mistakes over and over again. It indicates to them we’re not listening. If a reviewer knows they’re likely to have to give an author the same points of review many times they’re going to be less inclined to review that author’s PRs.
Addenda
High Cohesion, Low Coupling
Code cohesion subjectively describes how well defined the role of a piece of code is. Highly cohesive code has a clear purpose. Maybe it’s to solve a specific problem, maybe it’s to define the workflow of many smaller pieces of code, maybe it handles I/O. Highly cohesive code is easy to read because it’s clear what its intent is. This makes it more straightforward to maintain, modify, review, and test.
Code coupling defines the complexity of a dependency tree, mostly within the same project. It is more than simply the imports at the top of a file. Low coupling is about keeping your dependency tree (at the function and inheritance level, not simply at the “import ...” level) shallow and acyclic. We don’t have control over 3rd party dependencies so typically the concept of coupling is not extended to cover these. “Shallow” is, like cohesion, subjective.
Cohesion and coupling are a balancing act. As we increase cohesion by breaking code into smaller functional units, we also increase coupling. Similarly we can reduce coupling by putting all our code into a handful of huge functions, but this will also reduce cohesion. Hopefully it’s self evident that neither of these extremes produces easy to understand, and therefore maintainable, code.